OS0x0
2025年11月15日 · 4998 字 · 10 分钟
总结一些OS知识点,也算是rcore这么久以来的总结以及期末复习参考。笔者能力有限不保证绝对正确(x)
basic
什么是操作系统
rcore中的描述是:
操作系统是一种系统软件,主要功能是向下管理CPU、内存和各种外设等硬件资源,并形成软件执行环境来向上管理和服务应用软件
操作系统本质上是一段运行在物理内存中的代码,特殊在:
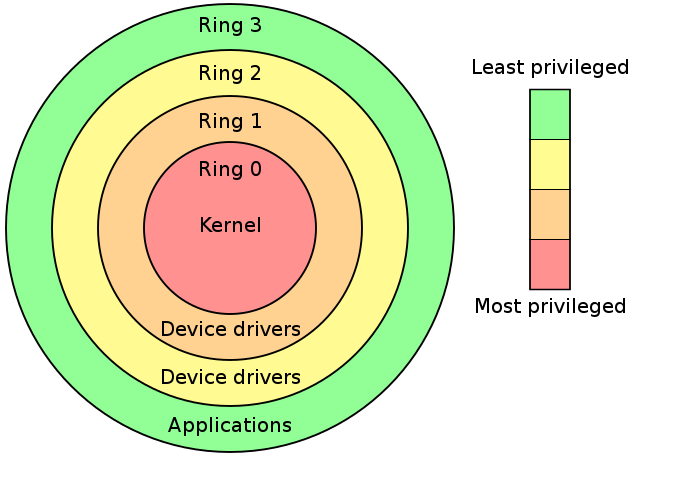
硬件赋权 (Hardware-Enforced Privilege): 它运行在 Ring 0 (Kernel Mode),是CPU硬件给予的物理特权,只有处于这个模式,才能执行特权指令(如修改 CR3 寄存器切换页表、读写 MSR、执行 I/O 指令)
-
用户态:CPU 运行在 ring3 + 用户进程运行环境上下文
-
内核态:CPU 运行在 ring0 + 内核代码运行环境上下文
而开发者们创造了系统调用(syscall)这个机制,让用户态程序可以通过受控的方式切换到内核态,进而使用操作系统提供的各种服务
抽象的创造者:物理硬件是丑陋且有限的(有限的 RAM、复杂的磁盘扇区、单个 CPU 核心) 操作系统创造了完美的幻觉:
-
每个进程都觉得拥有无限且连续的内存(虚拟内存)
-
每个进程都觉得独占了 CPU(时间片调度)
-
每个进程都觉得磁盘就是一连串字节流(文件系统)
进程
进程 = 运行环境上下文 + 内核数据结构(PCB)
运行环境上下文:
寄存器状态(包括指令指针、栈指针等)
虚拟地址空间(由页表定义)
内核数据结构:
task_struct(进程描述符)
包含PCB、权限凭证、调度信息等
执行上下文通过进程控制块(PCB)保存所有通用寄存器、指针作令和状态寄存器,而进程切换本质就是保存当前进程的执行上下文,加载下一个进程的执行上下文
每个进程都在内核态有一个独立的虚拟地址空间(内核栈)
不同进程的虚拟地址空间相互隔离
通过页表映射到不同的物理内存
实现内存保护和安全隔离
页表是cpu内存管理单元MMU能读懂的内存映射数据结构
操作系统通过维护页表来实现虚拟内存管理,页表记录了虚拟地址到物理地址的映射关系,当进程访问内存时,MMU会根据页表将虚拟地址转换为物理地址
每个进程拥有独立的页表集,不同进程的虚拟地址空间相互隔离,通过页表映射到不同的物理内存,实现内存保护和安全隔离

进程调度
由于需要运行的进程数量远大于CPU数量,不能让某几个进程占据所有CPU,操作系统通过进程调度算法来实现对CPU的合理分配
时钟中断(timer interrupt)是操作系统实现进程调度的关键机制,CPU定期触发时钟中断,操作系统在中断处理程序中保存当前进程的执行上下文,选择下一个进程并加载其执行上下文,从而实现进程切换
在进程调度时,我们保存当前进程的上下文到对应PCB中并取出的一个进程的PCB,从其中恢复带运行进程的上下文
内核
- 控制并与硬件进行交互
- 提供应用程式运行环境
- 调度系统资源
微内核&宏内核&混合内核
分级保护域
将计算机不同的资源划分至不同权限
x86-64 架构:CS (代码段) 寄存器的最低 2 位(RPL/CPL)
00 = Ring 0 (Kernel), 11 = Ring 3 (User)
RISC-V架构:CSR寄存器中的状态位(mstatus/sstatus),M-Mode (Machine, 固件级), S-Mode (Supervisor, 内核级), U-Mode (User, 用户级)
虚拟内存空间
计算机的虚拟内存地址空间通常被分为两块——供用户进程使用的用户空间(user space)与供操作系统内核使用的内核空间(kernel space),对于 Linux 而言,通常位于较高虚拟地址的虚拟内存空间被分配给内核使用,而位于较低虚拟地址的虚拟内存空间责备分配给用户进程使用
- 不同进程的用户空间映射隔离
- 所有进程共享相同的内核空间映射
运行状态切换与控制流转移
从用户态到内核态的三种途径
系统调用:主动请求内核服务
异常(Exception):非法操作(如除零、缺页等)
中断(Interrupt):外部硬件事件
syscall
用户把参数塞进寄存器(RISC-V a0-a7,x86 rdi, rsi…),把系统调用号塞进 rax/a7,然后执行特殊指令,CPU 硬件会自动跳转到在初始化时设置好的入口地址(stvec/MSR_LSTAR)
中断
中断本质是CPU控制流的强制转移机制
中断 (Interrupt)
├── 外部中断 (External Interrupt) - 硬中断
│ ├── 可屏蔽中断 (Maskable) - IF标志位控制
│ │ ├── 时钟中断 (Timer)
│ │ ├── 键盘中断 (Keyboard)
│ │ ├── 网卡中断 (Network)
│ │ └── 磁盘中断 (Disk I/O)
│ │
│ └── 不可屏蔽中断 (NMI) - 无法通过IF屏蔽
│ ├── 硬件故障
│ └── 内存错误
│
└── 内部中断 - 软中断/异常
├── 异常 (Exception) - 错误引发
│ ├── 故障 (Fault) - 可恢复
│ │ ├── 缺页异常 (#PF)
│ │ └── 段错误 (#GP)
│ │
│ ├── 陷阱 (Trap) - 调试用
│ │ ├── 断点异常 (#BP)
│ │ └── 单步执行 (#DB)
│ │
│ └── 终止 (Abort) - 不可恢复
│ └── 双重故障 (#DF)
│
└── 软件中断 (Software Interrupt)
├── int n 指令主动触发
└── 系统调用 (int 0x80)
信号机制
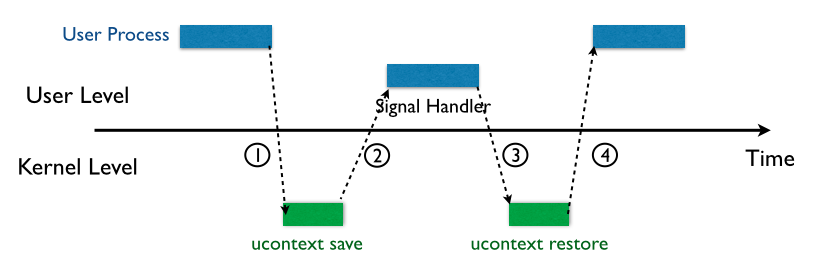
袜SROP还在追我
过程①,内核会向进程发送一个signal(你可以把这个理解为中断信号),意思是接下来该进程被挂起,此刻由内核来接管
过程②,内核会保存该进程在用户态的上下文,并且跳到已经注册好的Signal Handler(信号处理器),当这个Signal Handler返回的时候,内核控制去传递了一串user-space code (用户层代码),这里翻译成用户层代码可能不是特别准确,我想表达的意思是,这就是一串实现函数功能的代码并且处于在了用户层,并且这部分代码被称作signal trampoline
过程③,它是在执行signal trampoline的过程
过程④,内核将恢复之前保存的上下文,并且最后恢复进程的执行
进程权限管理
kernel 调度着一切的系统资源,并为用户应用程式提供运行环境,相应地,应用程式的权限也都是由 kernel 进行管理的
每个进程有三个cred:
real_cred:客体凭证,进程的原始权限
cred:主体凭证,当前有效权限(内核以此判断权限)
ptracer_cred:使用ptrace系统调用跟踪该进程的上级进程的cred(gdb调试便是使用了这个系统调用,常见的反调试机制的原理便是提前占用了这个位置)
cred结构体:
//include/linux/cred.h
struct cred {
atomic_t usage;
#ifdef CONFIG_DEBUG_CREDENTIALS
atomic_t subscribers; /* number of processes subscribed */
void *put_addr;
unsigned magic;
#define CRED_MAGIC 0x43736564
#define CRED_MAGIC_DEAD 0x44656144
#endif
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
unsigned securebits; /* SUID-less security management */
kernel_cap_t cap_inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
kernel_cap_t cap_ambient; /* Ambient capability set */
#ifdef CONFIG_KEYS
unsigned char jit_keyring; /* default keyring to attach requested
* keys to */
struct key *session_keyring; /* keyring inherited over fork */
struct key *process_keyring; /* keyring private to this process */
struct key *thread_keyring; /* keyring private to this thread */
struct key *request_key_auth; /* assumed request_key authority */
#endif
#ifdef CONFIG_SECURITY
void *security; /* subjective LSM security */
#endif
struct user_struct *user; /* real user ID subscription */
struct user_namespace *user_ns; /* user_ns the caps and keyrings are relative to. */
struct group_info *group_info; /* supplementary groups for euid/fsgid */
/* RCU deletion */
union {
int non_rcu; /* Can we skip RCU deletion? */
struct rcu_head rcu; /* RCU deletion hook */
};
} __randomize_layout;
真实用户ID(real UID):标识一个进程启动时的用户ID
保存用户ID(saved UID):标识一个进程最初的有效用户ID
有效用户ID(effective UID):标识一个进程正在运行时所属的用户ID,一个进程在运行途中是可以改变自己所属用户的,因而权限机制也是通过有效用户ID进行认证的,内核通过 euid 来进行特权判断;为了防止用户一直使用高权限,当任务完成之后,euid 会与 suid 进行交换,恢复进程的有效权限
文件系统用户ID(UID for VFS ops):标识一个进程创建文件时进行标识的用户ID
root的uid/gid均为0
进程权限改变
提权的本质:修改进程的cred结构体
I/O
万物皆文件,linux将一切都使用访问文件的方式进行操作
所有的读取操作都可以通过对文件进行 read 系统调用完成
所有的更改操作都可以通过对文件进行 write 系统调用完成
所有的配置操作都可以通过对文件进行 ioctl 系统调用完成
进程文件系统
进程文件系统(process file system, 简写为procfs)用以描述一个进程,其中包括该进程所打开的文件描述符、堆栈内存布局、环境变量等等
进程文件系统本身是一个伪文件系统,通常被挂载到/proc目录下,并不真正占用储存空间,而是占用一定的内存
当一个进程被建立起来时,其进程文件系统便会被挂载到/proc/[PID]下,我们可以在该目录下查看其相关信息
文件描述符
每个进程都有一个文件描述符表(file descriptor table),用以记录该进程所打开的文件描述符(file descriptor, 简写为fd)
0: stdin(标准输入)
1: stdout(标准输出)
2: stderr(标准错误)
3+: 后续打开的文件
文件描述符是进程级别的,不同进程的fd相互独立
内核维护全局文件表,fd是对该表的索引
ioctl系统调用
int ioctl(int fd, unsigned long request, ...);
fd:设备的文件描述符
request:请求码
其他参数:可选参数,取决于请求码
ioctl系统调用允许用户程序通过文件描述符与设备驱动程序进行交互,发送控制命令或获取设备状态信息
Loadable Kernel Module (LKM)
可加载内核模块(Loadable Kernel Module, 简写为LKM)是一种可以在操作系统运行时动态加载和卸载的内核代码模块
动态加载/卸载:运行时插拔
运行在内核空间:Ring 0权限
ELF格式:类似可执行文件
典型应用:设备驱动程序
常见命令:
lsmod:列出已加载的内核模块
insmod:插入内核模块
rmmod:移除内核模块
modinfo:显示模块信息
内核内存结构&管理
三级结构:页→区→节点
节点(Node) - pglist_data
└─ 区(Zone) - struct zone
├─ ZONE_DMA # 用于DMA的低端内存
├─ ZONE_NORMAL # 正常可用内存
└─ ZONE_HIGHMEM # 高端内存(32位系统)
└─ 页(Page) - struct page
-
NUMA vs UMA:
- UMA(统一内存访问):所有CPU访问内存延迟相同,只有1个节点
- NUMA(非统一内存访问):每个CPU有本地内存,访问本地快、远程慢
双重内存分配器
伙伴系统 (Buddy System)
struct zone {
//...
struct free_area free_area[MAX_ORDER];
//...
在每个 zone 结构体中都有一个 free_area 结构体数组,用以存储 buddy system 按照 order 管理的页面
MAX_ORDER 为一个常量,值为 11
- 粒度:以页(通常4KB)为单位
- 机制:按2的幂次方管理连续页框
- 优点:减少外部碎片
- Order范围:0~11,对应1页到2048页
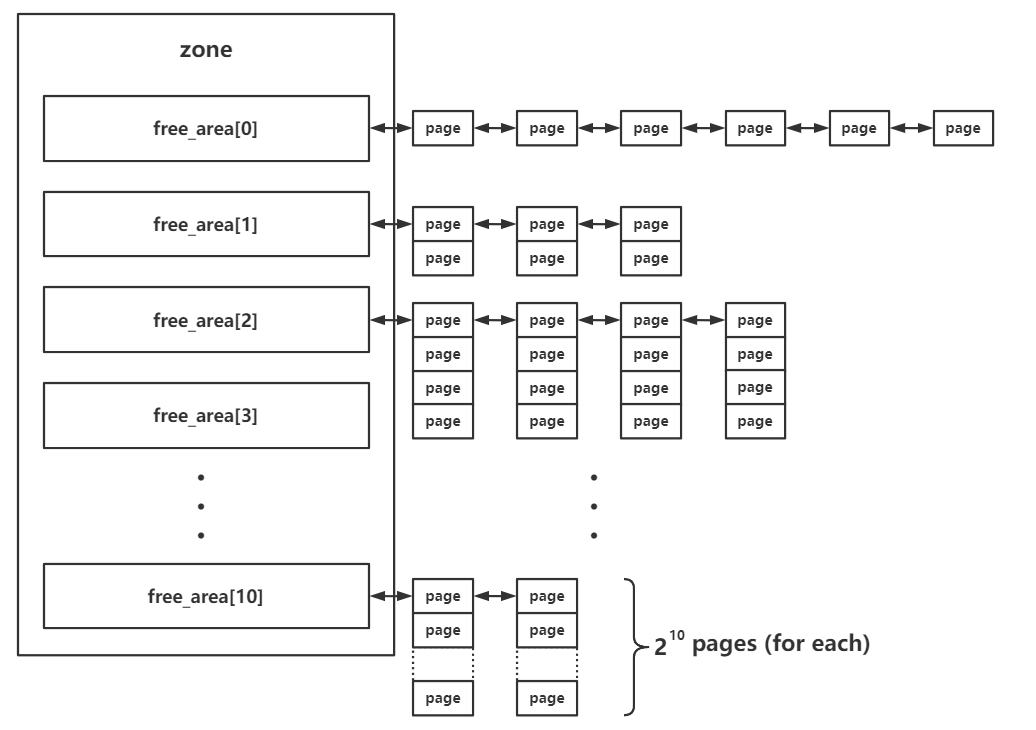
- 分配:
- 首先会将请求的内存大小向 2 的幂次方张内存页大小对齐,之后从对应的下标取出连续内存页
- 若对应下标链表为空,则会从下一个 order 中取出内存页,一分为二,装载到当前下标对应链表中,之后再返还给上层调用,若下一个 order 也为空则会继续向更高的 order 进行该请求过程
- 释放:
- 将对应的连续内存页释放到对应的链表上
- 检索是否有可以合并的内存页,若有,则进行合成,放入更高 order 的链表中,一路向上合并
SLAB分配器 (SLAB Allocator)
- 粒度:以对象(object)为单位
- 机制:从buddy system获取页面后切分成小对象
- 优点:减少内部碎片,适合频繁分配/释放的小对象
- 结构:
kmem_cache (针对特定大小)
├─ kmem_cache_cpu (percpu,无锁快速路径)
│ └─ 当前使用的slub
└─ kmem_cache_node (所有CPU共享)
├─ partial链表 (部分使用的slub)
└─ full链表 (完全分配的slub)
- 优先从kmem_cache_cpu取(无锁,最快)
- 其次从partial链表取
- 最后向buddy system申请新页
Slab 的空闲块里存放着“下一个空闲块的地址”
保护机制
KASLR
原理:内核加载时添加随机偏移
局限:内核内部相对偏移不变,泄露一个地址即可计算所有地址
绕过:信息泄露漏洞
FGKASLR
原理:以函数粒度随机化内核代码布局
优势:即使泄露一个函数地址,也无法推断其他函数位置
代价:性能开销增加
STACK PROTECTOR
类似于用户态程序的 canary,通常又被称作是 stack cookie,用以检测是否发生内核堆栈溢出,若是发生内核堆栈溢出则会产生 kernel panic
内核中的 canary 的值通常取自 gs 段寄存器某个固定偏移处的值
SMAP/SMEP
- SMEP (Supervisor Mode Execution Prevention):防止内核执行用户空间代码
- SMAP (Supervisor Mode Access Prevention):防止内核访问用户空间数据
- 实现:CR4寄存器第20位控制
- 绕过方法:
- kernel ROP修改CR4寄存器关闭SMEP
- ret2dir:利用直接映射区访问
KPTI
- 原理:用户态和内核态使用不同页表
- 用户页表:映射用户空间+最小内核代码
- 内核页表:完整映射
- 代价:上下文切换性能损失(5-30%)
堆保护机制
Hardened Usercopy
保护对象:用户空间↔内核空间的数据拷贝
检查内容:是否越界读写
局限:不保护内核内部拷贝
绕过:使用内核到内核的拷贝函数
Hardened Freelist
原始: next指针 = 下一个free object地址
加固: next指针 = 当前地址 XOR 下一个地址 XOR random值
Random Freelist
原理:新slub的object链接顺序随机化
注意:仅在初始化时随机,运行时仍遵循LIFO
CONFIG_INIT_ON_ALLOC
效果:分配时清零内存
目的:防止未初始化内存泄露
代价:1-7%性能损失
Stack Protector
机制:在栈上放置canary
来源:GS段寄存器某固定偏移处
触发:检测到canary被破坏时kernel panic