ch4
2025年10月29日 · 7553 字 · 16 分钟
这段时间得复健一下CTF准备省赛,写完这节之后得搁置一段时间哩,等省赛结束恶补进度……
4.1虚拟地址与地址空间
“每个进程独占一个虚拟地址空间”的幻象
虚拟地址:应用程序访问内存时使用的地址,由操作系统通过地址空间抽象提供,应用程序仅能访问自己的虚拟地址空间,无法直接操作物理内存。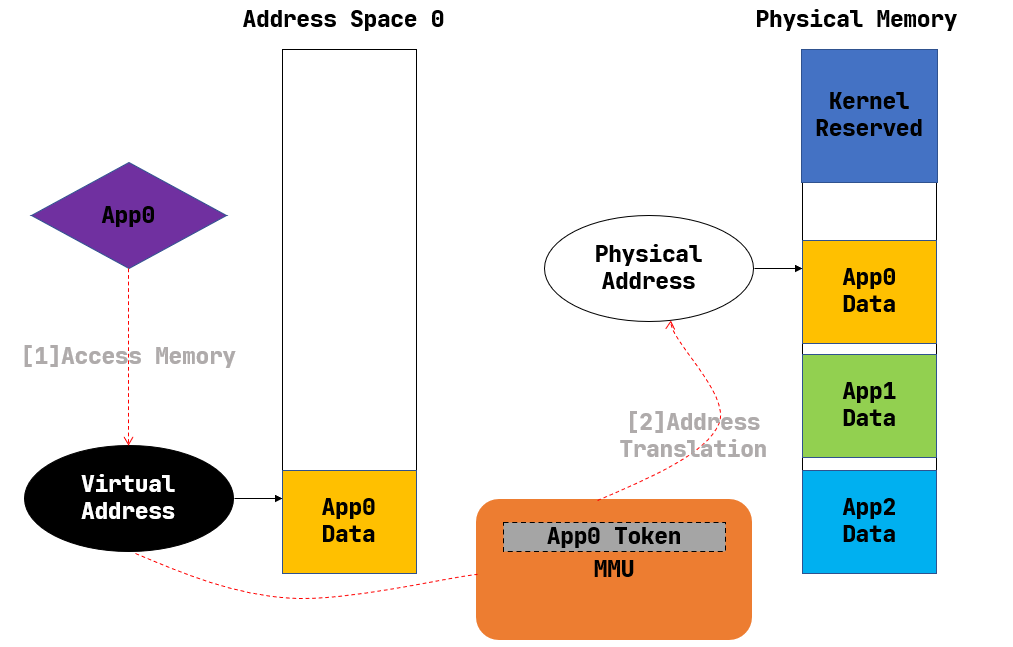
地址空间:对某一进程(或执行上下文)可见的逻辑连续地址集合,是一个连续的虚拟内存区域,包含应用程序的代码段、数据段、堆和栈等逻辑段,每个应用独占自己的地址空间,MMU会根据一个映射表查询虚拟地址对应的物理地址, 这个映射表就叫页表, 根页表的地址存放在指定的寄存器中, riscv中是satp寄存器,x86中是CR3,loongarch中是PGD CSR
地址转换:CPU的内存管理单元(MMU)将虚拟地址转换为物理地址。若转换失败(如地址无效或权限不足),处理器触发内存访问异常。
4.2分段内存管理
将地址空间划分为逻辑段,每个段在物理内存中连续存放,通过基址和边界寄存器进行地址转换与保护,消除了内碎片(段大小按需分配),提高内存利用率,同时物理内存中产生不连续的小块空闲区域,无法满足大段分配需求,通过复杂连续内存分配算法整理碎片,MMU需为每个段维护基址和边界寄存器,任务切换时需更新这些寄存器,开销较大
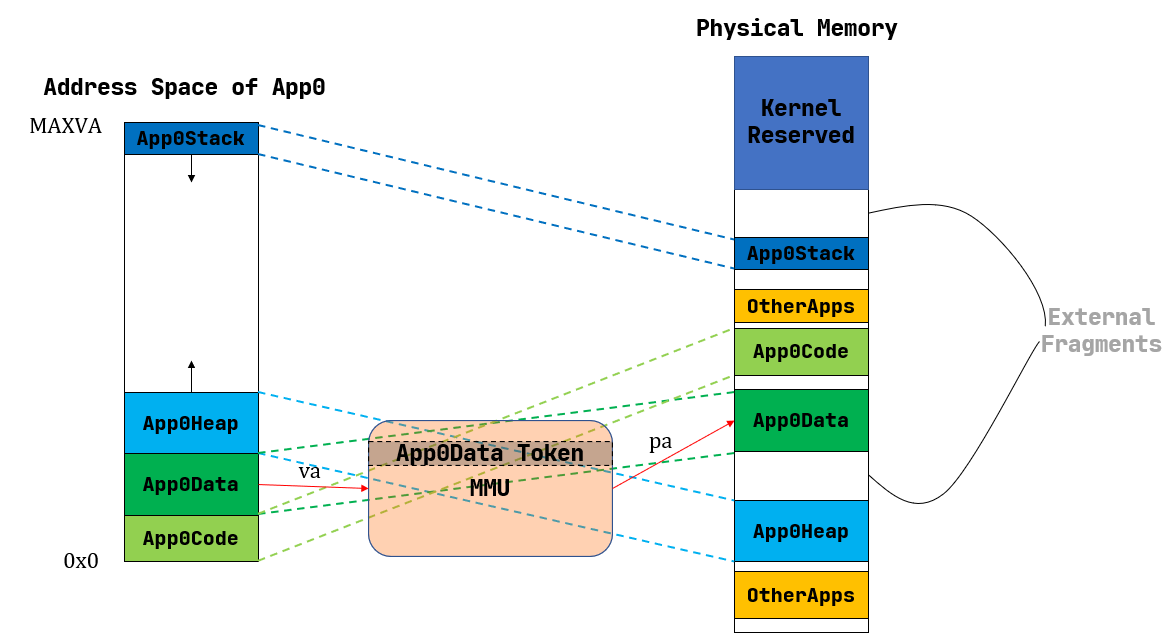
4.3分页内存管理
将虚拟地址空间与物理内存都划分为大小相同的固定单元——页与页帧,虚拟页面通过页表映射到物理页帧,内存分配以页为单位

页表映射:为了追踪哪些虚拟页对应于物理内存中的哪些页帧,操作系统维护着一张映射表,这就是所谓的页表。当程序尝试访问其虚拟内存中的数据时,操作系统查看页表来找出那个虚拟页在物理内存中的位置
内存访问:当程序访问一个虚拟地址时,这个地址被分成两部分:页号和页内偏移。页号用于在页表中查找对应的物理页帧,而页内偏移决定了在这个页帧内的具体位置
缺页中断:如果程序需要访问的页当前不在物理内存中(也就是说,它在硬盘的交换空间里),这会触发一个叫做缺页中断(page fault)的事件。操作系统随后会选择一个物理页(如果需要,可能会将当前的内容保存到硬盘上),并从硬盘上加载所需的虚拟页到这个物理页中,然后更新页表,并重新开始执行刚才中断的指令
页替换算法:当物理内存满了,而需要加载新的页时,操作系统必须决定哪些页将被移出物理内存以为新页腾出空间。这涉及到页替换算法,如最近最少使用(LRU)、先进先出(FIFO)等,用于选择被替换的页
通常现代操作系统使用 改进型 Clock 算法(Second Chance 或 NRU),综合考虑访问位和修改位
页表内主要包含:
物理页号:用于地址转换。
标志位:用于控制访问权限和记录页面状态。
4.4SV39 多级页表的硬件机制
 RISC-V 64 架构下 satp 的字段分布:
RISC-V 64 架构下 satp 的字段分布:
MODE:控制CPU使用哪种页表实现,设置为0的时候,代表所有访存都被视为物理地址,设置为8的时候,SV39分页机制被启用,所有S/U特权级的访存被视为一个39位的虚拟地址,它们需要先经过MMU的地址转换流程,如果顺利的话,则会变成一个56位的物理地址来访问物理内存;否则则会触发异常
ASID:表示地址空间标识符,这里还没有涉及到进程的概念,我们不需要管这个地方;
PPN:存的是根页表所在的物理页号,给定一个虚拟页号,CPU就可以从三级页表的根页表开始一步步的将其映射到一个物理页号。
地址格式:

[38:30]:一级页表索引(VPN[2])
[29:21]:二级页表索引(VPN[1])
[20:12]:三级页表索引(VPN[0])
[11:0]:页内偏移(offset)
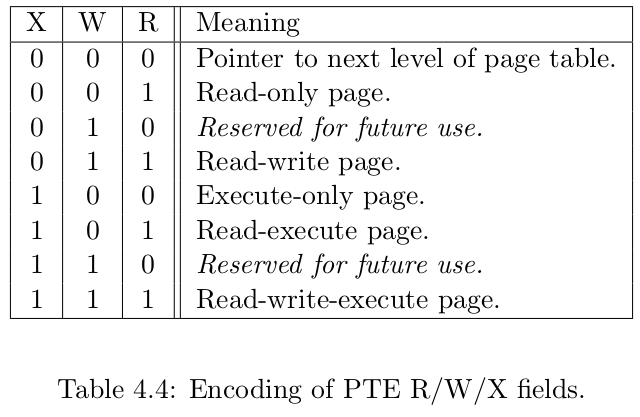
SV39 中的 R/W/X 组合的含义:
地址翻译缓存(TLB):由于地址翻译过程可能相当耗时,因为它涉及到多次内存访问,RISC-V处理器通常会使用TLB来缓存最近的地址翻译结果,来加快地址翻译速度
地址转换过程:
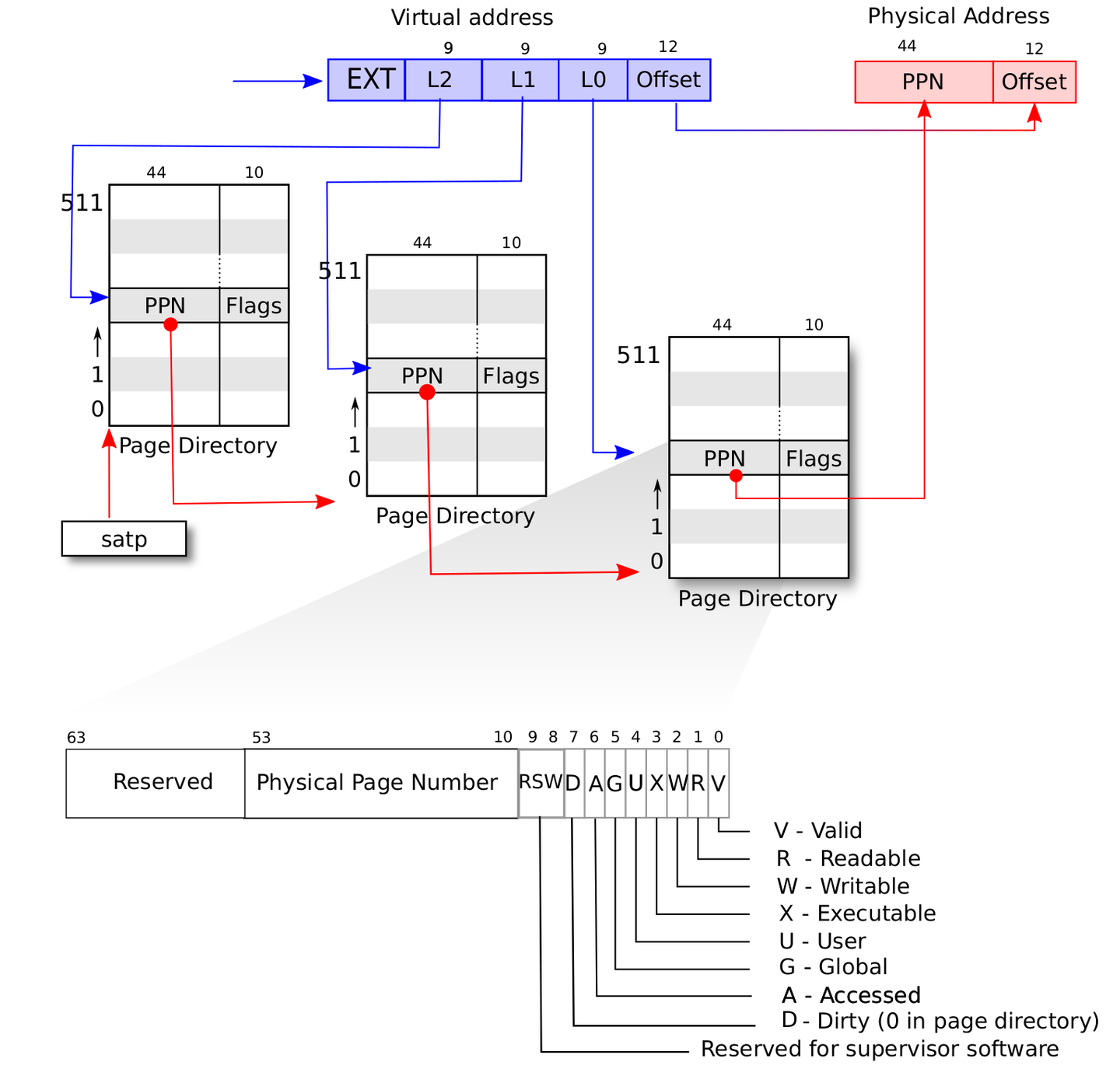
L2是根页表的索引, 2 = 512正好能表示所有的索引, 根页表的页表项记录了L1对应页表的物理页号PPN
用之前拿到的物理页号PPN找到L1对应页表的物理页, 用同样的思路找到索引L1的页表项, 其记录了L0对应页表的物理页号PPN
用之前的PPN, 结合索引L0拿到实际的数据页的页号PPN
用最终得到的页号PPN找到数据页, 使用页内偏移offSet就找到了最终的物理地址
SV39分页数据结构
地址和页号抽象:
// os/src/mm/address.rs
#[derive(Copy, Clone, Ord, PartialOrd, Eq, PartialEq)]
pub struct PhysAddr(pub usize);
#[derive(Copy, Clone, Ord, PartialOrd, Eq, PartialEq)]
pub struct VirtAddr(pub usize);
#[derive(Copy, Clone, Ord, PartialOrd, Eq, PartialEq)]
pub struct PhysPageNum(pub usize);
#[derive(Copy, Clone, Ord, PartialOrd, Eq, PartialEq)]
pub struct VirtPageNum(pub usize);
提供:
floor() / ceil():页边界对齐;
page_offset():取页内偏移;
vpn():虚拟地址 → 页号
页帧分配与回收:
pub struct StackFrameAllocator {
current: usize,
end: usize,
recycled: Vec<usize>,
}
impl StackFrameAllocator {
pub fn init(&mut self, l: PhysPageNum, r: PhysPageNum) {
self.current = l.0;
self.end = r.0;
// trace!("last {} Physical Frames.", self.end - self.current);
}
}
// os/src/mm/frame_allocator.rs
impl FrameAllocator for StackFrameAllocator {
fn alloc(&mut self) -> Option<PhysPageNum> {
if let Some(ppn) = self.recycled.pop() {
Some(ppn.into())
} else {
if self.current == self.end {
None
} else {
self.current += 1;
Some((self.current - 1).into())
}
}
}
fn dealloc(&mut self, ppn: PhysPageNum) {
let ppn = ppn.0;
// validity check
if ppn >= self.current || self.recycled
.iter()
.find(|&v| {*v == ppn})
.is_some() {
panic!("Frame ppn={:#x} has not been allocated!", ppn);
}
// recycle
self.recycled.push(ppn);
}
}
分配时优先从recycled中重复利用回收的页帧, 否则对current自增完成分配
回收时将其放入recycled
/// Allocate a physical page frame in FrameTracker style
pub fn frame_alloc() -> Option<FrameTracker> {
FRAME_ALLOCATOR
.exclusive_access()
.alloc()
.map(FrameTracker::new)
}
/// Deallocate a physical page frame with a given ppn
pub fn frame_dealloc(ppn: PhysPageNum) {
FRAME_ALLOCATOR.exclusive_access().dealloc(ppn);
}
pub struct FrameTracker {
/// physical page number
pub ppn: PhysPageNum,
}
impl Drop for FrameTracker {
fn drop(&mut self) {
frame_dealloc(self.ppn);
}
}
将一个物理页帧的生命周期绑定到一个 FrameTracker 变量上,当其生命周期结束时, 使用自定义的drop方法通过之前实现的 frame_dealloc将其回收到StackFrameAllocator的recycle容器中以供后续使用
手动查询页表:
/// Find PageTableEntry by VirtPageNum, create a frame for a 4KB page table if not exist
fn find_pte_create(&mut self, vpn: VirtPageNum) -> Option<&mut PageTableEntry> {
let idxs = vpn.indexes();
let mut ppn = self.root_ppn;
let mut result: Option<&mut PageTableEntry> = None;
for (i, idx) in idxs.iter().enumerate() {
let pte = &mut ppn.get_pte_array()[*idx];
if i == 2 {
result = Some(pte);
break;
}
if !pte.is_valid() {
let frame = frame_alloc().unwrap();
*pte = PageTableEntry::new(frame.ppn, PTEFlags::V);
self.frames.push(frame);
}
ppn = pte.ppn();
}
result
}
/// Find PageTableEntry by VirtPageNum
fn find_pte(&self, vpn: VirtPageNum) -> Option<&mut PageTableEntry> {
let idxs = vpn.indexes();
let mut ppn = self.root_ppn;
let mut result: Option<&mut PageTableEntry> = None;
for (i, idx) in idxs.iter().enumerate() {
let pte = &mut ppn.get_pte_array()[*idx];
if i == 2 {
result = Some(pte);
break;
}
if !pte.is_valid() {
return None;
}
ppn = pte.ppn();
}
result
}
find_pte_create 在建立新映射时按需创建缺失的页表 find_pte查询现有映射时不创建页表,遇到无效项返回None 均实现了前文提到的三级索引查找
建立和拆除虚实地址映射关系:
// os/src/mm/page_table.rs
impl PageTable {
pub fn map(&mut self, vpn: VirtPageNum, ppn: PhysPageNum, flags: PTEFlags) {
let pte = self.find_pte_create(vpn).unwrap();
assert!(!pte.is_valid(), "vpn {:?} is mapped before mapping", vpn);
*pte = PageTableEntry::new(ppn, flags | PTEFlags::V);
}
pub fn unmap(&mut self, vpn: VirtPageNum) {
let pte = self.find_pte_create(vpn).unwrap();
assert!(pte.is_valid(), "vpn {:?} is invalid before unmapping", vpn);
*pte = PageTableEntry::empty();
}
}
根据虚拟页号找到页表项,然后修改或者直接清空其内容
4.5内核与应用的地址空间
数据结构
pub struct MemorySet {
page_table: PageTable,
areas: Vec<MapArea>,
}
MemorySet就是一个地址空间,PageTable下挂着所有多级页表的节点所在的物理页帧,Vec< MapArea >下则挂着对应逻辑段中的数据所在的物理页帧,这两部分 合在一起构成了一个地址空间所需的所有物理页帧
pub struct MapArea {
vpn_range: VPNRange,
data_frames: BTreeMap<VirtPageNum, FrameTracker>,
map_type: MapType,
map_perm: MapPermission,
}
MapArea的vpn_range描述一段虚拟页号的连续区间,表示该逻辑段在地址区间中的位置和长度,表示虚拟页号的返回, data_frames同样是将FrameTracker的生命周期绑定到BTreeMap中
新建和拆除Maprea映射:
pub fn map_one(&mut self, page_table: &mut PageTable, vpn: VirtPageNum) {
let ppn: PhysPageNum;
match self.map_type {
MapType::Identical => {
ppn = PhysPageNum(vpn.0);
}
MapType::Framed => {
let frame = frame_alloc().unwrap();
ppn = frame.ppn;
self.data_frames.insert(vpn, frame);
}
}
let pte_flags = PTEFlags::from_bits(self.map_perm.bits).unwrap();
page_table.map(vpn, ppn, pte_flags);
}
#[allow(unused)]
pub fn unmap_one(&mut self, page_table: &mut PageTable, vpn: VirtPageNum) {
if self.map_type == MapType::Framed {
self.data_frames.remove(&vpn);
}
page_table.unmap(vpn);
}
新建一个虚拟页到物理页的映射:
- 如果映射类型是MapType::Framed: 从 FRAME_ALLOCATOR 处分配一个物理页frame, 并将 vpn 和 frame 插入到 data_frames 中
- 如果映射类型是MapType::Identical, ppn和vpn相等
无论是哪种类型, 都在page_table中插入vpn到ppn的映射
unmap_one思路类似,也是调用PageTable的unmap方法
MapArea只是逻辑上管理一个虚拟地址段的数据结构, 真正的映射实现还是通过外部提供的PageTable的map实现, 正因如此, MapArea需要被托管到上层的结构体进行管理
在所有虚拟页中调用这两个方法就实现了整个地址空间的建立和拆除
pub fn map(&mut self, page_table: &mut PageTable) {
for vpn in self.vpn_range {
self.map_one(page_table, vpn);
}
}
#[allow(unused)]
pub fn unmap(&mut self, page_table: &mut PageTable) {
for vpn in self.vpn_range {
self.unmap_one(page_table, vpn);
}
}
内核地址空间
64位地址空间在SV39分页模式下实际可能通过MMU检查的最高256GiB:
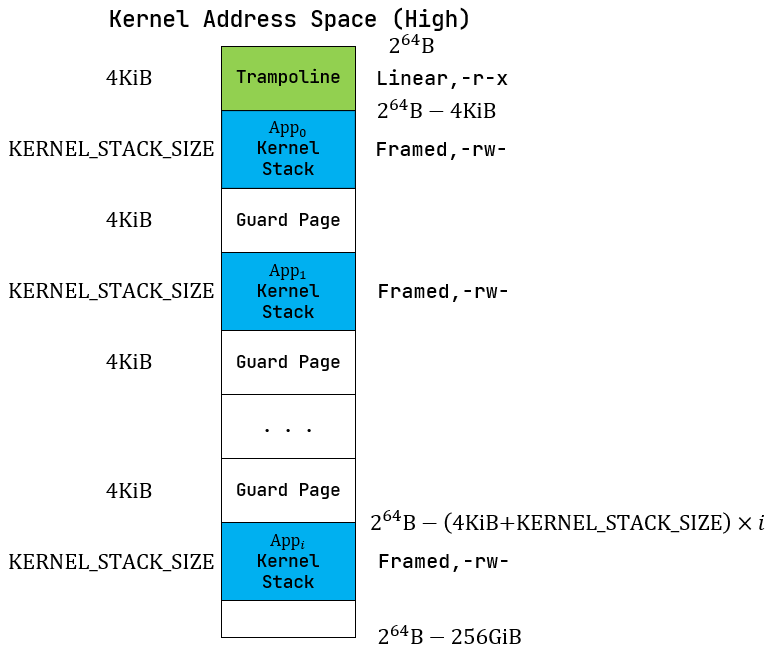 内核地址空间的低 256GiB:
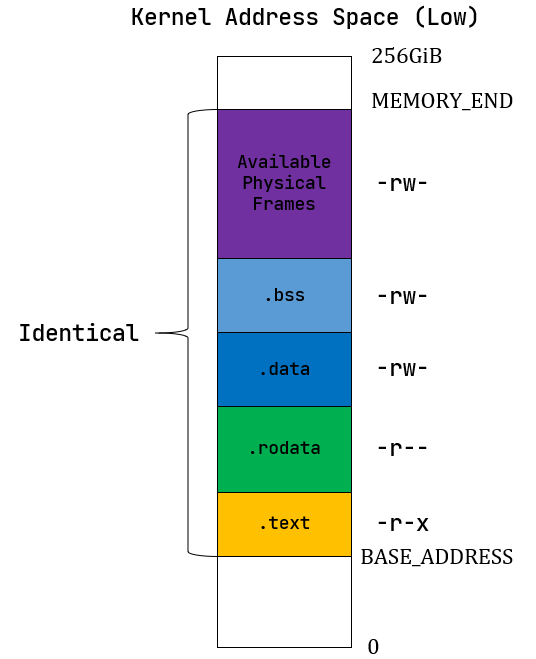
内核地址空间的低 256GiB:
 应用地址空间布局:
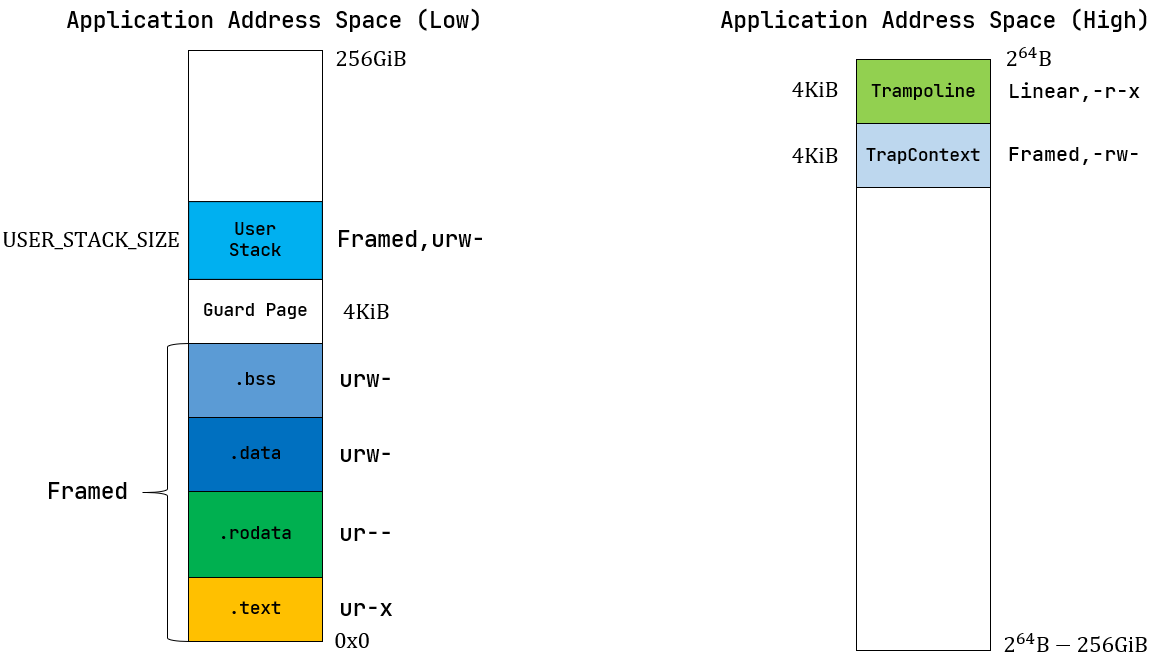
应用地址空间布局:
跳板的实现
引入虚拟地址后,trap上下文保存的实现也需要改变,分析ch4的tarp.S:
.altmacro
.macro SAVE_GP n
sd x\n, \n*8(sp)
.endm
.macro LOAD_GP n
ld x\n, \n*8(sp)
.endm
.section .text.trampoline
.globl __alltraps
.globl __restore
.align 2
__alltraps:
csrrw sp, sscratch, sp
# now sp->*TrapContext in user space, sscratch->user stack
# save other general purpose registers
sd x1, 1*8(sp)
# skip sp(x2), we will save it later
sd x3, 3*8(sp)
# skip tp(x4), application does not use it
# save x5~x31
.set n, 5
.rept 27
SAVE_GP %n
.set n, n+1
.endr
# we can use t0/t1/t2 freely, because they have been saved in TrapContext
csrr t0, sstatus
csrr t1, sepc
sd t0, 32*8(sp)
sd t1, 33*8(sp)
# read user stack from sscratch and save it in TrapContext
csrr t2, sscratch
sd t2, 2*8(sp)
# load kernel_satp into t0
ld t0, 34*8(sp)
# load trap_handler into t1
ld t1, 36*8(sp)
# move to kernel_sp
ld sp, 35*8(sp)
# switch to kernel space
csrw satp, t0
sfence.vma
# jump to trap_handler
jr t1
__restore:
# a0: *TrapContext in user space(Constant); a1: user space token
# switch to user space
csrw satp, a1
sfence.vma
csrw sscratch, a0
mv sp, a0
# now sp points to TrapContext in user space, start restoring based on it
# restore sstatus/sepc
ld t0, 32*8(sp)
ld t1, 33*8(sp)
csrw sstatus, t0
csrw sepc, t1
# restore general purpose registers except x0/sp/tp
ld x1, 1*8(sp)
ld x3, 3*8(sp)
.set n, 5
.rept 27
LOAD_GP %n
.set n, n+1
.endr
# back to user stack
ld sp, 2*8(sp)
sret
在ch3中,由于内核栈和用户栈公用一套地址空间,所以在陷入和离开trap时只需要反复交换栈指针,但引入虚拟空间后,内核和用户的地址空间不一样, 也就是satp中的根页表地址不一样,因此陷入内核时需要将内核地址空间的根页表地址(token)写入satp, 因此需要一个寄存器存储原来用户空间的token, 同时用户栈的指针也需要被存储, 但我们只有一个 sscratch 寄存器可用来进行周转。因此我们没有办法像原来一样将应用程序的上下文信息保存在内核栈中
-
当用户态发生Trap时,硬件将当前特权级切换为S模式,保存当前的sepc、sstatus等寄存器,跳转至stvec所指定的入口地址__alltraps
-
此时sp仍然指向用户栈,sscratch 被设置为应用地址空间中Trap上下文(TrapContext)所在位置的地址(通常位于应用地址空间的次高页面)。
-
__alltraps执行csrrw sp, sscratch, sp,交换sp和sscratch,此时sp指向Trap上下文(TrapContext)位置,sscratch保存用户栈指针,以sp为基准,保存所有通用寄存器和关键 CSR
这一步完成后,Trap 上下文已经完全保存在应用地址空间中,内核可安全切换页表。
__alltraps第30行后:
-
将内核地址空间的 token(页表基址)加载到 t0;
-
将内核 Trap Handler 的入口地址加载到 t1;
-
将内核栈顶地址加载到 sp;
执行:
csrw satp, t0
sfence.vma
切换到内核页表
最后jr t1跳转到内核Trap Handler的入口
⚠️ 这里使用 jr 而不是 call,跳转指令实际被执行时的虚拟地址和在编译器/汇编器/链接器进行后端代码生成和链接形成最终机器码时设置此指令的地址是不同的
因为不能依赖 call-ret 链接,jr 直接跳转最安全
在 __restore 中:
先执行:
csrw satp, a1
sfence.vma
切换回用户页表
将a0(Trap上下文地址)写入sscratch
这样下一次Trap时硬件能正确使用
将sp设置为Trap上下文地址
依次恢复通用寄存器与CSR(sepc、sstatus等)
最后执行:
sret
从S模式返回U模式,恢复到用户态执行
由于地址空间发生了变化,trap.S中的代码在内核地址空间和用户地址空间必须是相同的映射, 这一块映射的地址段就是Trampoline
// os/src/config.rs
pub const TRAMPOLINE: usize = usize::MAX - PAGE_SIZE + 1;
// os/src/mm/memory_set.rs
fn map_trampoline(&mut self) {
self.page_table.map(
VirtAddr::from(TRAMPOLINE).into(),
PhysAddr::from(strampoline as usize).into(),
PTEFlags::R | PTEFlags::X,
);
}
map_trampoline方法直接被一个地址空间映射, 不属于一个MapArea,直接在多级页表中插入一个从地址空间的最高虚拟页面映射到跳板汇编代码所在的物理页帧的键值对,访问方式限制与代码段相同,即RX
pub fn new_kernel() -> Self {
let mut memory_set = Self::new_bare();
// map trampoline
memory_set.map_trampoline();
// map kernel sections
info!(".text [{:#x}, {:#x})", stext as usize, etext as usize);
info!(".rodata [{:#x}, {:#x})", srodata as usize, erodata as usize);
info!(".data [{:#x}, {:#x})", sdata as usize, edata as usize);
info!(
".bss [{:#x}, {:#x})",
sbss_with_stack as usize, ebss as usize
);
info!("mapping .text section");
memory_set.push(
MapArea::new(
(stext as usize).into(),
(etext as usize).into(),
MapType::Identical,
MapPermission::R | MapPermission::X,
),
None,
);
...
}
4.6任务控制
pub struct TaskControlBlock {
/// Save task context
pub task_cx: TaskContext,
/// Maintain the execution status of the current process
pub task_status: TaskStatus,
/// Application address space
pub memory_set: MemorySet,
/// The phys page number of trap context
pub trap_cx_ppn: PhysPageNum,
/// The size(top addr) of program which is loaded from elf file
pub base_size: usize,
}
添加地址空间MemorySet的结构体以及每个任务的trap context的物理页号tarp_cx_ppn, 这样内核才可以在任务控制时获取其trap的上下文信息
base_size 统计了应用数据的大小,也就是在应用地址空间中从0x0开始到用户栈结束一共包含多少字节,后续还应该包含用于应用动态内存分配的堆空间的大小
改进trap
在Trap处理中,我们首先将stvec设置为内核Trap处理函数的地址,然后根据Trap原因进行处理,处理完成后,调用trap_return返回用户态
在trap_return中,我们将stvec设置为用户Trap处理函数的地址(即跳板页面的地址),然后准备好参数,分别是Trap上下文在应用地址空间中的虚拟地址和要继续执行的应用 地址空间的 token,跳转到__restore(在跳板页面中)恢复上下文并返回用户态
改写sys_write
将应用地址空间中一个缓冲区转化为在内核空间中能够直接访问的形式的辅助函数,以向量的形式返回一组可以在内核空间中直接访问的字节数组切片:
// os/src/mm/page_table.rs
/// Translate&Copy a ptr[u8] array with LENGTH len to a mutable u8 Vec through page table
pub fn translated_byte_buffer(token: usize, ptr: *const u8, len: usize) -> Vec<&'static mut [u8]> {
let page_table = PageTable::from_token(token);
let mut start = ptr as usize;
let end = start + len;
let mut v = Vec::new();
while start < end {
let start_va = VirtAddr::from(start);
let mut vpn = start_va.floor();
let ppn = page_table.translate(vpn).unwrap().ppn();
vpn.step();
let mut end_va: VirtAddr = vpn.into();
end_va = end_va.min(VirtAddr::from(end));
if end_va.page_offset() == 0 {
v.push(&mut ppn.get_bytes_array()[start_va.page_offset()..]);
} else {
v.push(&mut ppn.get_bytes_array()[start_va.page_offset()..end_va.page_offset()]);
}
start = end_va.into();
}
v
}
将每个字节数组切片转化为字符串&str然后输出:
// os/src/syscall/fs.rs
pub fn sys_write(fd: usize, buf: *const u8, len: usize) -> isize {
match fd {
FD_STDOUT => {
let buffers = translated_byte_buffer(current_user_token(), buf, len);
for buffer in buffers {
print!("{}", core::str::from_utf8(buffer).unwrap());
}
len as isize
},
_ => {
panic!("Unsupported fd in sys_write!");
}
}
}
总之就是通过页表翻译访问用户空间数据并支持跨地址空间的字符串输出
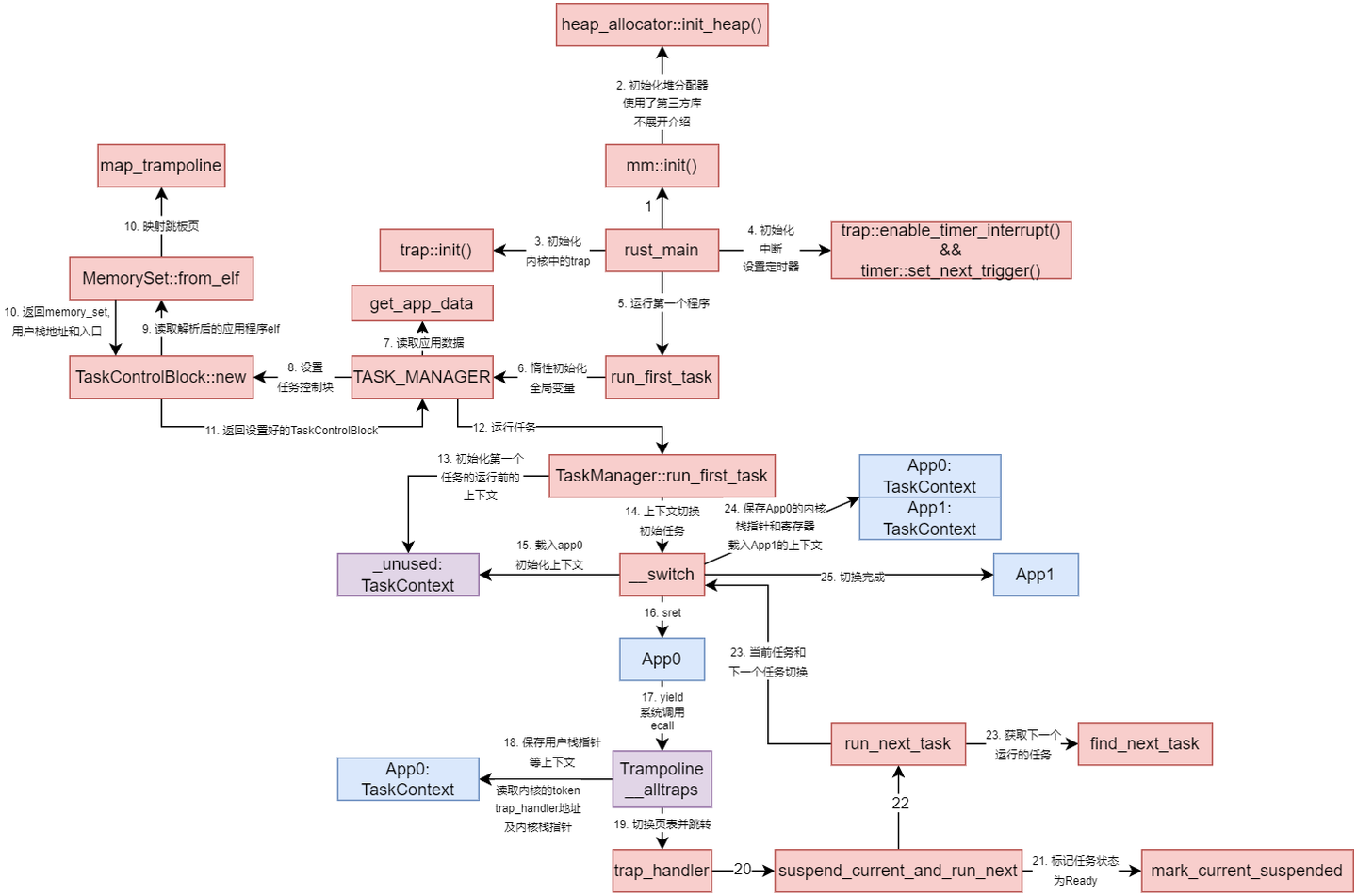 图源知乎
图源知乎
4.7 ch4练习
实现功能:
- 重写sys_trace
- 为 MemorySet 增加页面取消映射功能,支持 munmap 实现
- translated_refmut< T >:通过页表token获取用户空间指针的内核可写引用
- read_one_bytes:读取用户空间1字节
- write_one_bytes:写入用户空间1字节
- sys_mmap和sys_munmap实现动态内存映射与释放,检查了页对齐、权限位是否合法,权限位映射:R/W/X → MapPermission,通过 TASK_MANAGER 调用底层 task_mmap / task_munmap 执行实际操作
- 沿用ch3写的inc_current_syscall_count / get_current_syscall_count统计系统调用统计接口
- 实现时间获取系统支持通过页表翻译访问用户空间的TimeVal结构
简答作业
1
63 54 53 28 27 19 18 10 9 8 7 6 5 4 3 2 1 0
+----------+------------+------------+------------+------+-+-+-+-+-+-+-+-+
| Reserved | PPN[2] | PPN[1] | PPN[0] | RSW |D|A|G|U|X|W|R|V|
+----------+------------+------------+------------+------+-+-+-+-+-+-+-+-+
10bits 26bits 9bits 9bits 2bits 8 flag bits
| 标志位 | 名称 | 作用 |
|---|---|---|
| V (bit 0) | Valid | 有效位:为1表示该PTE有效,为0表示无效(会触发缺页异常) |
| R (bit 1) | Read | 可读位:为1表示该页面可读 |
| W (bit 2) | Write | 可写位:为1表示该页面可写 |
| X (bit 3) | Execute | 可执行位:为1表示该页面可执行 |
| U (bit 4) | User | 用户态访问位:为1表示用户态可访问,为0表示仅内核态可访问 |
| G (bit 5) | Global | 全局映射位:为1表示该映射在所有地址空间都有效(TLB不会因为ASID改变而失效)用于性能优化,它允许某些页表项在多个上下文之间共享,减少TLB刷新 |
| A (bit 6) | Accessed | 访问位:硬件自动设置,表示该页面被访问过,帮助操作系统确定哪些页面是活跃的,哪些页面可以被换出内存 |
| D (bit 7) | Dirty | 脏位:硬件自动设置,表示该页面被写入过,帮助操作系统确定哪些页面是活跃的,哪些页面可以被换出内存。 |
| RSW (bit 8-9) | Reserved for Software | 软件保留位:供操作系统软件使用,常用于实现COW写时复制,用于实现fork系统调用时的内存效率优化 |
- R=0, W=1, X=0:保留组合,会触发异常
- R=0, W=0, X=0, V=1:表示这是一个指向下一级页表的指针(非叶子节点)
- 至少一个RWX位为1:表示这是叶子节点,指向实际的物理页面
2.1 根据RISC-V规范,以下异常可能是缺页导致的:
Instruction Page Fault (异常码 12)
取指令时,对应虚拟地址的页面不在页表中或无执行权限
Load Page Fault (异常码 13)
执行load指令访问内存时,目标页面不在页表中或无读权限
Store/AMO Page Fault (异常码 15)
执行store或原子操作指令时,目标页面不在页表中或无写权限
2.2
| 寄存器 | 描述 |
|---|---|
| scause | 存储异常原因码(12/13/15,对应上述三种Page Fault) |
| sepc | 存储触发异常的指令地址(PC值),用于异常处理完成后返回重新执行 |
| stval | 关键:存储引发缺页的虚拟地址(访问失败的目标地址) |
| sstatus | 存储异常发生前的处理器状态(SPP位记录来自用户态还是内核态) |
| satp | 当前页表基址寄存器,指示当前使用的页表 |
2.3
节省内存:未访问的页面不会被真正分配物理内存
加快启动速度:程序加载更快,因为无需立即建立所有页表
减少 I/O:比如 .text 段只在第一次执行某函数时才从磁盘加载
支持更大的虚拟地址空间:无需实际分配全部对应物理页
2.4
10G = 10 × 2³⁰ 字节 = 10 × 2³⁰ / 2¹² 页 = 10 × 2¹⁸ 页 ≈ 2.62M 个页面
SV39 三级页表:
每个页表页:512 个PTE × 8字节 = 4KB(正好一页)
第三级页表(叶子):2.62M / 512 ≈ 5120 页 = 20MB
第二级页表:5120 / 512 ≈ 10 页 = 40KB
第一级页表:1 页 = 4KB
约20MB + 40KB + 4KB ≈ 20MB
2.5 & 2.6 当mmap或brk增大堆区时,只更新虚拟地址空间结构体(VMA),不分配物理页,页表中对应项标记为无效 (V=0),或R/W/X=0
当进程第一次访问该页时,触发缺页异常处理函数分配物理页面,并更新页表项 区分未分配页面和换出页面swap:
全零 PTE:从未分配
V=0 但其他位非零:已换出到磁盘
缺页处理时,查找磁盘上相应的数据(如果之前已经映射),然后加载到内存中
3.1
单页表 = 用户态与内核态共用一张页表 当切换进程时,需更换satp寄存器指向新进程的根页表(因为不同进程的虚拟空间不同),包含了当前活动页表的物理地址
3.2
通过PTE的U(User)位,只靠权限位即可区分访问:
对于内核页:U=0 → 用户态访问将触发异常(load/store page fault)
对于用户页:U=1 → 用户态可访问,内核态也可访问
3.3
无需切换页表:系统调用/中断时不需要修改satp,减少开销
TLB不失效:进入内核态时内核地址的TLB条目仍然有效
更少的TLB miss:内核和用户的TLB条目共存
内核访问用户数据更方便
每个进程只需一个页表,节省内存
3.4
双页表:
用户态执行 → 使用用户页表(user satp)
陷入内核 → 切换到内核页表(kernel satp)
返回用户态 → 再切回用户页表
单页表 OS:
只在进程切换时(context switch)更换页表
进入/退出内核态时不换页表,只靠U位权限控制
fork 创建子进程
荣誉准则
-
在完成本次实验的过程(含此前学习的过程)中,我曾分别与以下各位 就(与本次实验相关的)以下方面做过交流,还在代码中对应的位置以注释形式记录了具体的交流对象及内容:
无 -
此外,我也参考了 以下资料 ,还在代码中对应的位置以注释形式记录了具体的参考来源及内容:
无 -
我独立完成了本次实验除以上方面之外的所有工作,包括代码与文档。 我清楚地知道,从以上方面获得的信息在一定程度上降低了实验难度,可能会影响起评分。
-
我从未使用过他人的代码,不管是原封不动地复制,还是经过了某些等价转换。 我未曾也不会向他人(含此后各届同学)复制或公开我的实验代码,我有义务妥善保管好它们。 我提交至本实验的评测系统的代码,均无意于破坏或妨碍任何计算机系统的正常运转。 我清楚地知道,以上情况均为本课程纪律所禁止,若违反,对应的实验成绩将按“-100”分计。